
Table of Contents
The Parallel Letter Frequency problem on Exercism’s Elixir Track is a medium difficulty problem that I found really interesting to solve. If you haven’t seen the problem before, you’re tasked with writing a function that can calculate the frequency of letters in a list of strings. Sounds simple enough, right? Well, it also needs to handle non-English characters and do the calculation concurrently with a user-controlled number of workers:
iex> Frequency.frequency(["Freude", "schöner", "Götterfunken"], num_workers)
%{
"c" => 1,
"d" => 1,
"e" => 5,
...
"ö" => 2
}
Simply throwing /[a-z]/ at this problem is not going to cut it.
Luckily for all you Alchemists out there, Elixir has core features that make meeting these extra requirements quite easy. But – if you’re like me – you might have never used or even heard of them. The features I’m talking about are Unicode matching in the Regex module and using the Task module to write asynchronous/concurrent code.
Prior to solving this problem I barely knew about these features, but I would now consider them an indispensible part of my Elixir toolbox. To me, this really demonstrates the value of Exercism even for more-experienced developers: solving challenging “synthetic” problems pushes you to learn and apply parts of your language that you may not have explored. Often this new learning lets you solve “real world” problems in your production code in a more efficient or expressive way. This was certainly the case for me with this specific problem.
In this article I’ll show you how you can apply Unicode matches and the Task module to solve the Parallel Letter Frequency problem in Elixir. I’ll also show that although concurrency might be seen as a “free” way to make your code faster, in some cases it can have the opposite effect. The concurrent code in my solution ran around 80% faster on my system for certain workloads, but in some cases was over 3x slower than the original code. As the benchmarks later in the post demonstrate, depending on the situation, adding concurrency can actually reduce performance while also increasing the complexity of your code.
✅ View my published solution on Exercism.
Determine whether a character is a letter in Elixir
How would you use Elixir to determine whether or not "a" is a letter?
I think most people would apply a regular expression like /[a-z]/:
iex> String.match?("a", ~r/^[a-z]$/)
true
What about "A"?
Adding the i (case insensitive) modifier would probably be the easiest way:
iex> String.match?("A", ~r/^[a-z]$/i)
true
Ok, now what about "ö"?
If you’re like me a week ago, you might be struggling to think of the best solution –[a-z] is definitely not going to work:
iex> String.match?("ö", ~r/^[a-z]$/i)
false
Determining whether or not "ö" is a letter is a core part of solving this Exercism problem, since one of the texts thrown at you in the tests is in German:
# Poem by Friedrich Schiller. The corresponding music is the European Anthem.
@ode_an_die_freude """
Freude schöner Götterfunken
...
"""
Initially I thought I could use a regular expression to check if a character isn’t a special character, but decided that was a dead end. A regular expression like that was going to be long, inelegant and fragile; I was not confident that I could list every special character that could possibly come up, and it seemed to be the wrong way to approach the problem anyway.
Unicode regular expressions in Elixir
Digging deeper, I learned about the u modifier in Elixir’s Regex module:
unicode (
u) - enables Unicode specific patterns like\pand change modifiers like\w,\W,\sand friends to also match on Unicode.
It turns out that the u modifier – and specifically the \p pattern – was exactly what I needed. The \p pattern lets you match a grapheme (another name for a single Unicode character) in any of the Unicode character categories. This not only includes specific categories like Ll (Letter, lowercase) and Sc (Symbol, currency), but also the parent categories like L (Letter) and S (Symbol).
You can match any letter of any case in any human language covered by Unicode with the pattern \p{L}. This is super powerful, and exactly what I needed to solve the problem. Converting this regular expression to Elixir form – ~r/^\p{L}$/u – I was able to match any single Unicode letter in Elixir:
iex> String.match?("a", ~r/^\p{L}$/u)
true
iex> String.match?("A", ~r/^\p{L}$/u)
true
iex> String.match?("ö", ~r/^\p{L}$/u)
true
iex> String.match?("$", ~r/^\p{L}$/u)
false
I applied this specific regular expression in the count_letters/1 function of my solution. This function accepts a list of graphemes, ["a", "A", "ö", "$"], and returns a map that counts only the letters while ignoring the case, %{"a" => 2, "ö" => 1}:
defp count_letters(graphemes) do
Enum.reduce(graphemes, %{}, fn grapheme, acc ->
if String.match?(grapheme, ~r/^\p{L}$/u) do
downcased_letter = String.downcase(grapheme)
Map.update(acc, downcased_letter, 1, fn count -> count + 1 end)
else
acc
end
end)
end
How to make your code concurrent using the Task module
The other major challenge in solving this problem was adding concurrency. The function is required to do the letter frequency calculation by distributing the work to a number of worker processes, which the user can set with the workers argument.
While Elixir allows you to very easily spawn processes with something like Kernel.spawn_link/1, you’re much better off using the awesomely powerful abstractions provided by the Task module:
The most common use case for [Task] is to convert sequential code into concurrent code by computing a value asynchronously.
The Task module lets you write unbelievably clean concurrent code in Elixir – no callback hell and no need for Promises.
I decided that Task.async_stream/5 was the best option in the Task toolbox for this particular problem:
async_stream(enumerable, module, function, args, options \\ [])
Task.async_stream/5 returns a stream that runs the given module, function, and args concurrently on each item in enumerable. There are two ways to control the level of concurrency with Task.async_stream/5:
- The number of items in
enumerable, which determines the number of workers spawned (in the absence of the:max_concurrencyoption) - Setting the
:max_concurrencyoption to the number of workers, given that the number of items inenumerableis greater than or equal to:max_concurrency
I chose the first option for my solution since it was the easiest for me to understand and also meant that I could ensure that the correct number of workers was used even for very short strings. Here’s a diagram of my approach to adding concurrency to this problem:
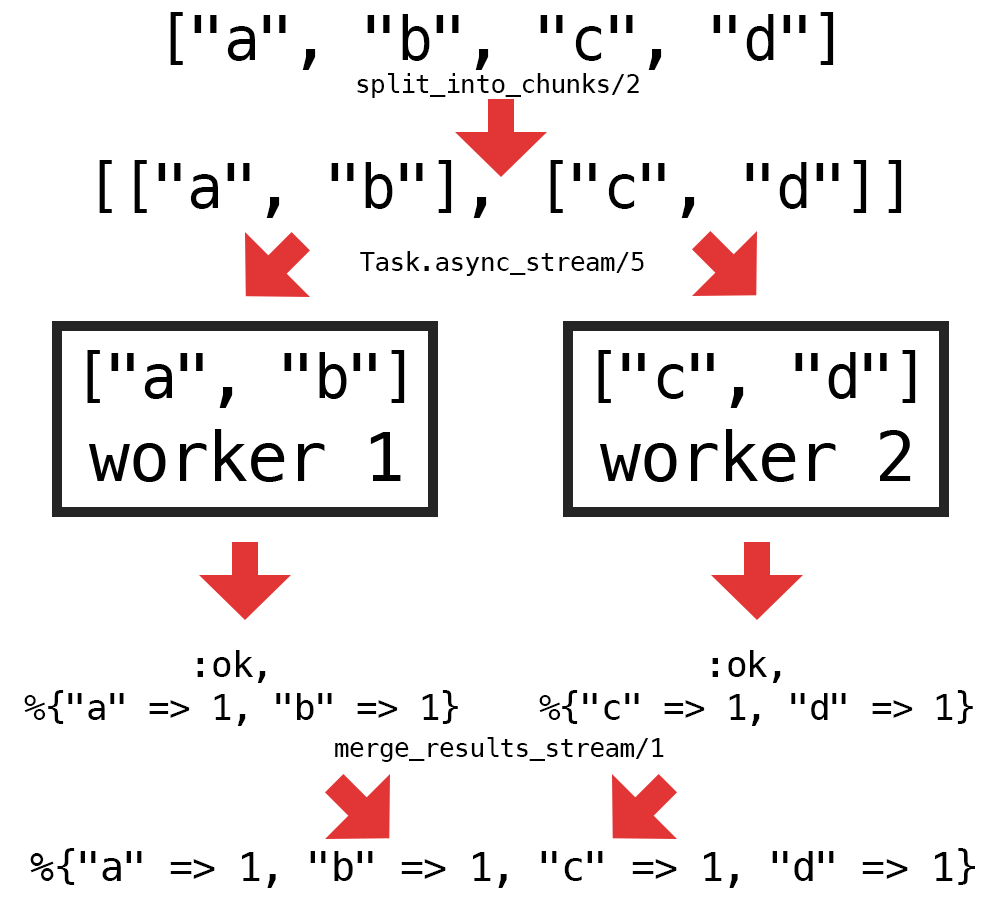
Or in words:
- Split up a list of graphemes into a number of chunks (equal to the number of workers)
- Process each chunk in a worker using
Task.async_stream/5 - Merge the results from each worker into a single result
My implementation using Task.async_stream/5 is shown below (using the count_letters/1 function from the previous section). Notice how this reads exactly like regular sequential code, despite potentially massive concurrency. Such is the power of the abstractions provided in Task:
def frequency(texts, workers) do
texts
|> get_all_graphemes()
|> split_into_chunks(workers)
|> Task.async_stream(__MODULE__, :count_letters, [])
|> merge_results_stream()
end
defp split_into_chunks(all_graphemes, num_chunks) do
all_graphemes_count = Enum.count(all_graphemes)
graphemes_per_chunk = :erlang.ceil(all_graphemes_count / num_chunks)
Enum.chunk_every(all_graphemes, graphemes_per_chunk)
end
defp merge_results_stream(results_stream) do
Enum.reduce(results_stream, %{}, fn {:ok, worker_result}, acc ->
Map.merge(acc, worker_result, fn _key, acc_val, worker_val ->
acc_val + worker_val
end)
end)
end
Does concurrency actually make the code faster?
I showed how I made the frequency/2 function concurrent in the previous section, but did it actually make the code faster? Theoretically, concurrency can speed up code on a system by distributing work across all available CPU cores. However, it’s a really good idea test this theory before accepting the additional complexity and potential fragility that concurrency adds to your code.
I split the clauses of the function based on the number of workers to allow me to test the concurrent and non-concurrent implementations separately:
def frequency([], _workers), do: %{}
def frequency(texts, 1) do
texts
|> get_all_graphemes()
|> count_letters()
end
def frequency(texts, workers) do
texts
|> get_all_graphemes()
|> split_into_chunks(workers)
|> Task.async_stream(__MODULE__, :count_letters, [])
|> merge_results_stream()
end
The original implementation of the function is called when workers == 1, and the concurrent implementation when workers > 1. I could then benchmark the function for the same input, with varying numbers of workers.
Benchmarking the function
There are a number of ways to benchmark Elixir code:
- Use
benchee, a package made specifically for benchmarking Elixir code - Use Erlang’s
:timer.tc/1to time how long an Elixir function takes to execute - Use the
timecommand found on Unix and Unix-like operating systems to time the execution of an Elixir script (.exs)
I felt that option 1 was the best overall; it required the most work, but gave the best results.
Since benchee is an external dependency, I first needed to convert the Frequency module into a Mix application.
Convert Frequency into a Mix application
I created a new Mix application called frequency with mix new:
$ mix new frequency
...
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd frequency
mix test
Run "mix help" for more commands.
Installed benchee:
# mix.exs
defp deps do
[
{:benchee, "~> 0.13", only: :dev}
]
end
$ cd frequency
$ mix deps.get
Resolving Hex dependencies...
Dependency resolution completed:
New:
benchee 0.13.2
deep_merge 0.2.0
* Getting benchee (Hex package)
* Getting deep_merge (Hex package)
And copied the contents of the original frequency.exs file into lib/frequency.ex:
# lib/frequency.ex
defmodule Frequency do
...
def frequency([], _workers), do: %{}
def frequency(texts, 1) do
...
def frequency(texts, workers) do
...
defp split_into_chunks(all_graphemes, num_chunks) do
...
defp merge_results_stream(results_stream) do
...
defp get_all_graphemes(texts) do
...
def count_letters(graphemes) do
...
end
Create a script that calls benchee to benchmark the code
Finally, I created an Elixir script that calls Benchee.run/2 to benchmark the function with different numbers of workers:
# benchmark.exs
duplicates =
System.argv()
|> List.first()
|> String.to_integer()
text = "The quick brown fox jumps over the lazy dog"
texts = List.duplicate(text, duplicates)
Benchee.run(%{
"original code" => fn -> Frequency.frequency(texts, 1) end,
"concurrent code: 2 workers" => fn -> Frequency.frequency(texts, 2) end,
"concurrent code: 4 workers" => fn -> Frequency.frequency(texts, 4) end,
"concurrent code: 8 workers" => fn -> Frequency.frequency(texts, 8) end
})
The texts variable is created by multiplying text a certain number of times. List.duplicate/2 is a convenient way of creating a large list of strings to pass to the frequency/2 function:
iex> List.duplicate("hello", 3)
["hello", "hello", "hello"]
The duplicates variable uses the first argument when calling the script from the command line, so I was able to vary the size of texts by changing the value of the argument.
For example, I could set duplicates to 1 by running:
$ mix run benchmark.exs 1
Or 1000 by running:
$ mix run benchmark.exs 1000
Concurrent vs non-current benchmark results
Benchmark results: duplicates == 1
$ mix run benchmark.exs 1
Operating System: macOS"
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.0
Erlang 21.1.1
...
Name ips average deviation median 99th %
original code 18.91 K 52.88 μs ±26.19% 49 μs 114 μs
concurrent code: 2 workers 8.96 K 111.59 μs ±26.41% 103 μs 230 μs
concurrent code: 4 workers 7.27 K 137.57 μs ±24.44% 125 μs 285 μs
concurrent code: 8 workers 6.00 K 166.76 μs ±22.26% 154 μs 329 μs
Comparison:
original code 18.91 K
concurrent code: 2 workers 8.96 K - 2.11x slower
concurrent code: 4 workers 7.27 K - 2.60x slower
concurrent code: 8 workers 6.00 K - 3.15x slower
Wow! For duplicates == 1, the concurrent code is slower than the original code by a significant amount. In fact, the code gets slower as the workers increase, with 8 workers being over 3 times slower than the original code.
I sort of expected this. The text is so short that with duplicates == 1 there is likely to be much more time spent in breaking up the text, spawning separate processes and merging the results than the actual letter frequency computation.
Benchmark results: duplicates == 100
$ mix run benchmark.exs 100
Operating System: macOS"
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.0
Erlang 21.1.1
...
Name ips average deviation median 99th %
concurrent code: 8 workers 190.34 5.25 ms ±10.34% 5.08 ms 7.24 ms
concurrent code: 4 workers 182.38 5.48 ms ±8.78% 5.34 ms 7.18 ms
concurrent code: 2 workers 176.21 5.67 ms ±8.98% 5.52 ms 7.55 ms
original code 159.70 6.26 ms ±9.47% 6.07 ms 8.71 ms
Comparison:
concurrent code: 8 workers 190.34
concurrent code: 4 workers 182.38 - 1.04x slower
concurrent code: 2 workers 176.21 - 1.08x slower
original code 159.70 - 1.19x slower
With duplicates == 100 the concurrent code started to perform better than the original code by a small margin. There was little difference between 4 and 8 workers, but both were around 20% faster than the original code.
For such a small improvement, the additional complexity added by the concurrent code is probably not worthwhile at this workload.
Benchmark results: duplicates == 1000
$ mix run benchmark.exs 1000
Operating System: macOS"
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.0
Erlang 21.1.1
...
Name ips average deviation median 99th %
concurrent code: 8 workers 28.04 35.66 ms ±17.33% 33.45 ms 56.97 ms
concurrent code: 4 workers 26.72 37.42 ms ±15.06% 35.69 ms 58.45 ms
concurrent code: 2 workers 20.84 47.98 ms ±11.75% 46.48 ms 73.73 ms
original code 15.34 65.21 ms ±12.37% 62.90 ms 88.35 ms
Comparison:
concurrent code: 8 workers 28.04
concurrent code: 4 workers 26.72 - 1.05x slower
concurrent code: 2 workers 20.84 - 1.35x slower
original code 15.34 - 1.83x slower
At duplicates == 1000 there was a significant difference between the original code and the concurrent code, with 4 and 8 workers both around 80% faster.
The difference between 4 and 8 workers was minimal, most likely because the number of physical cores on my system is 4. The value of 8 reported by benchee is due to my processor having Hyper-threading, which doubles the number of logical cores seen by the OS.
Benchmark results: duplicates == 10_000
$ mix run benchmark.exs 10000
Operating System: macOS"
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.0
Erlang 21.1.1
...
Name ips average deviation median 99th %
concurrent code: 8 workers 2.59 386.24 ms ±3.59% 388.54 ms 404.97 ms
concurrent code: 4 workers 2.40 417.01 ms ±5.90% 413.12 ms 464.11 ms
concurrent code: 2 workers 1.91 523.79 ms ±3.70% 525.62 ms 564.83 ms
original code 1.44 696.58 ms ±4.97% 690.44 ms 750.42 ms
Comparison:
concurrent code: 8 workers 2.59
concurrent code: 4 workers 2.40 - 1.08x slower
concurrent code: 2 workers 1.91 - 1.36x slower
original code 1.44 - 1.80x slower
At duplicates == 10_000 the concurrent code was still the clear victor. 8 workers performed the best on my system, at around 80% faster than the original non-concurrent implementation.
On average, 8 workers computed the result over 300ms faster than the original code (386ms vs 696ms), which is pretty significant.
Conclusion
In this post I walked you through how I used 2 awesome features of Elixir to help me solve the Parallel Letter Frequency problem on Exercism’s Elixir Track. I hope it’s been useful for you to be able see my approach to solving the problem and how you might use the Task module to add concurrency to your applications. A word of warning: as the benchmarks demonstrate, depending on your specific workload, adding concurrency can actually reduce performance while also making your code more complex. When in doubt, write the cleanest, most expressive code you can and test whether or not changes actually improve performance.
I was able to make the frequency/2 function run around 80% faster on my system for certain workloads by using 4 to 8 workers. This improvement could be crucial for your application – returning a result in around half the time could be the difference between acceptable and unusable. But if your application demands such high CPU performance for acceptable usability, Elixir may not be the correct technology choice.
This shouldn’t be interpreted as a criticism of Elixir’s Task module, which is an incredibly useful toolbox for writing asynchronous code with ease. Rather than applying Task for CPU-bound tasks like the letter frequency calculation, a better-suited application might be to make multiple HTTP requests concurrently, rather than waiting for each request to succeed/fail before making the next one. This could shave off hundreds of milliseconds and significantly improve the experience for users or your PageSpeed results.
Full solution code
defmodule Frequency do
@doc """
Count letter frequency in parallel.
Returns a map of characters to frequencies.
The number of worker processes to use can be set with 'workers'.
"""
@spec frequency([String.t()], pos_integer) :: map
def frequency([], _workers), do: %{}
def frequency(texts, 1) do
texts
|> get_all_graphemes()
|> count_letters()
end
def frequency(texts, workers) do
texts
|> get_all_graphemes()
|> split_into_chunks(workers)
|> Task.async_stream(__MODULE__, :count_letters, [])
|> merge_results_stream()
end
defp split_into_chunks(all_graphemes, num_chunks) do
all_graphemes_count = Enum.count(all_graphemes)
graphemes_per_chunk = :erlang.ceil(all_graphemes_count / num_chunks)
Enum.chunk_every(all_graphemes, graphemes_per_chunk)
end
defp merge_results_stream(results_stream) do
Enum.reduce(results_stream, %{}, fn {:ok, worker_result}, acc ->
Map.merge(acc, worker_result, fn _key, acc_val, worker_val ->
acc_val + worker_val
end)
end)
end
defp get_all_graphemes(texts) do
texts
|> Enum.join()
|> String.graphemes()
end
def count_letters(graphemes) do
Enum.reduce(graphemes, %{}, fn grapheme, acc ->
if String.match?(grapheme, ~r/^\p{L}$/u) do
downcased_letter = String.downcase(grapheme)
Map.update(acc, downcased_letter, 1, fn count -> count + 1 end)
else
acc
end
end)
end
end