
Table of Contents
Let’s imagine you’re developing an application that needs to make multiple independent API calls. A quick prototype might look like this:
# lib/my_app.ex
defmodule MyApp do
@urls [
"https://google.com/",
"https://github.com/",
"https://hexdocs.pm/",
"https://twitter.com/"
]
def call_apis() do
@urls
|> Enum.map(&HTTPoison.get/1)
end
end
The call_apis function is going to map over each url in @urls and make a HTTP request to each one with HTTPoison.get/1. This code is makes each request sequentially: it will wait until each request has finished before making the next request.
If each request is not dependent on the result of another, chances are we are wasting a lot of time by not making the requests concurrently.
Concurrent vs sequential HTTP requests
In theory, we could make this function significantly faster if we initiate all the requests at the same time and return once all of them are complete.
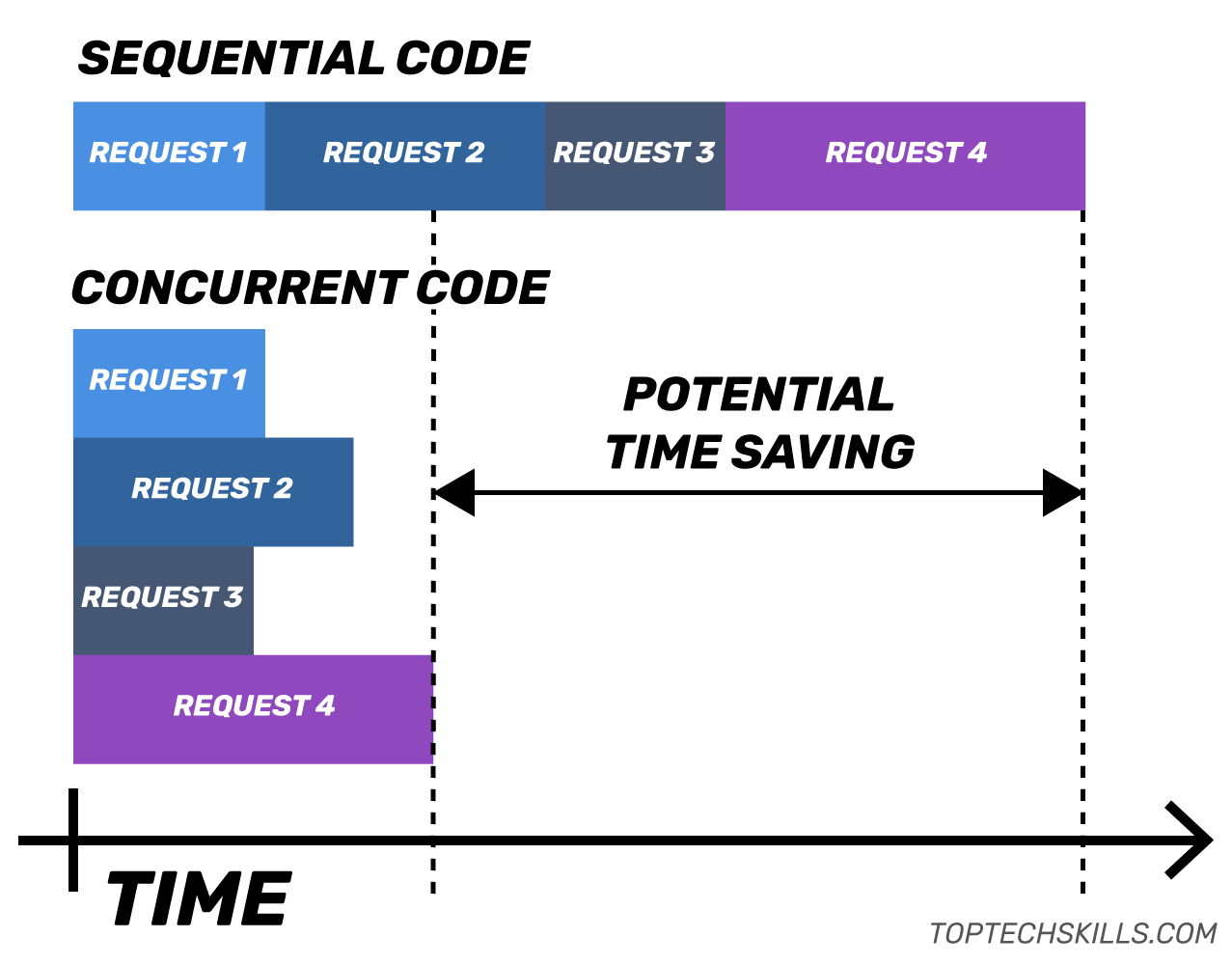
As the image above shows, in an ideal case, the concurrent code should only take as long as the longest single request. The sequential code takes as long as all the requests combined, as they are executed one after the other. That’s a big potential time saving.
Writing concurrent code in Elixir
One of the biggest selling points of Elixir/Erlang is that the BEAM VM is able to spawn “processes” and execute code concurrently inside them. While Elixir allows you to very easily spawn processes with functions like Kernel.spawn_link/1, you’re much better off using the awesomely powerful abstractions provided by the Task module:
The most common use case for [Task] is to convert sequential code into concurrent code by computing a value asynchronously.
For this example, I think the most useful functions in Task are Task.async_stream/3 and Task.async_stream/5:
async_stream(enumerable, fun, options \\ [])
async_stream(enumerable, module, function, args, options \\ [])
Both apply a function concurrently to each item in enumerable and return a stream of results. The stream can easily be consumed by functions in the Enum module, just like any other enumerable. Assuming there are no errors, the stream returned by Task.async_stream will be an enumerable with items {:ok, result}.
You can think of Task.async_stream/3 almost like a “concurrent Enum.map/2”:
iex> Enum.map(1..5, fn item -> item * 2 end)
[2, 4, 6, 8, 10]
iex> Task.async_stream(1..5, fn item -> item * 2 end) \
...> |> Enum.into([], fn {:ok, res} -> res end)
[2, 4, 6, 8, 10]
The biggest difference between the two commands above is that the second one did the calculation in 5 separate processes concurrently. Let’s see how we can apply this to the HTTP requests.
Making the call_apis function concurrent
Let’s use async_stream/3 to make a new, concurrent version of the call_apis/0 function, which I’ve called call_apis_async/0:
# lib/my_app.ex
defmodule MyApp do
@urls [
"https://google.com/",
"https://github.com/",
"https://hexdocs.pm/",
"https://twitter.com/"
]
def call_apis() do
@urls
|> Enum.map(&HTTPoison.get/1)
end
def call_apis_async() do
@urls
|> Task.async_stream(&HTTPoison.get/1)
|> Enum.into([], fn {:ok, res} -> res end)
end
end
All I’ve done is replace the single call to Enum.map/2 with calls to Task.async_stream/3 and Enum.into/3. No callback hell and no need for Promises. In fact, this looks like good ol’ sequential code!
Could such a tiny change make any difference to the performance of the function?
Applying Task.async_stream/3 should make each API call concurrently in a separate process, so theoretically there should be a performance improvement. However, we should never assume that a code change improves performance, so let’s go ahead and benchmark the code to make sure.
Benchmarking the two versions of the function
To check whether concurrency made any change at all to the performance, you can benchmark the functions with benchee.
All you need to do is add benchee to deps in mix.exs (and run mix deps.get):
# mix.exs
...
defp deps do
[
{:httpoison, "~> 1.4"},
{:benchee, "~> 0.13", only: :dev}
]
end
...
Then create a benchmark.exs (or whatever name you like) to benchmark the two functions:
# benchmark.exs
Benchee.run(
%{
"call_apis" => fn -> MyApp.call_apis() end,
"call_apis_async" => fn -> MyApp.call_apis_async() end
},
time: 10
)
I suggest adding the time: 10 option to make sure that the functions are called repeatedly for 10 seconds instead of the default 5 seconds.
You can run the benchmarks with mix run benchmark.exs:
$ mix run benchmark.exs
Operating System: macOS
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.1
Erlang 21.2.5
...
Name ips average deviation median 99th %
call_apis_async 2.61 0.38 s ±22.63% 0.37 s 0.55 s
call_apis 0.89 1.13 s ±13.08% 1.12 s 1.42 s
Comparison:
call_apis_async 2.61
call_apis 0.89 - 2.94x slower
It’s clear from the results that there is a massive difference between the two functions. The Comparison section shows that the call_apis_async function is almost 3 times faster than the call_apis function. More importantly though, call_apis took 1130ms, while call_apis_async took only 380ms, a full 750ms faster!
It turns out a tiny change made a not-so-tiny impact on the performance of the function.
Conclusion
Elixir’s Task module allows you to write unbelievably clean concurrent code. A two line change to the function above saved 750ms on average, which could be the difference between “fast” and “unacceptably slow” for your application.
# 😍
def call_apis_async() do
@urls
|> Task.async_stream(&HTTPoison.get/1)
|> Enum.into([], fn {:ok, res} -> res end)
end
Making HTTP requests concurrently is a perfect use case for Elixir’s Task module, and one of the few use cases that concurrency can reliably give performance improvements, which leads me to a warning…
BEWARE: adding concurrency is not a magic bullet for improving performance!
Always test your assumptions about performance by benchmarking your code. Depending on your specific workload, adding concurrency can actually reduce performance, so when in doubt, first write the cleanest, most expressive code you can and test whether or not concurrency actually improves performance.
For example, let’s look at the performance impact of concurrency on the Enum.map/2 snippet from above:
# benchmark.exs
Benchee.run(%{
"Enum.map/2" => fn -> Enum.map(1..5, fn item -> item * 2 end) end,
"Task.async_stream/3" => fn ->
Task.async_stream(1..5, fn item -> item * 2 end)
|> Enum.into([], fn {:ok, res} -> res end)
end
})
Running the benchmark:
$ mix run benchmark.exs
Operating System: macOS
CPU Information: Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
Number of Available Cores: 8
Available memory: 16 GB
Elixir 1.8.1
Erlang 21.2.5
....
Name ips average deviation median 99th %
Enum.map 1.64 M 0.61 μs ±6074.63% 0 μs 1 μs
Task.async_stream 0.0211 M 47.38 μs ±42.23% 41 μs 125.02 μs
Comparison:
Enum.map 1.64 M
Task.async_stream 0.0211 M - 77.52x slower
The concurrent code is over 77 times slower! This is mostly due to all the extra operations required compared to a simple Enum.map:
- Spawn new processes
- Await the results from all processes
- Merge the results with
Enum.into
These extra operations are pretty significant when compared to multiplying a number by 2. In the case of the HTTP requests, the overhead is still there, but is tiny compared to the time it takes to make a HTTP request.
So compared to Enum.map, adding concurrency has not only made the code slower, but it’s added complexity and potential fragility. I repeat: always test your assumptions and when in doubt, stick with clean sequential code.